Contents
Introduction
The most common use for JavaScript frameworks is to provide dynamic client-side user interface functionality for a web site. There are situations where a JS application does not require any services from its host server (see example unhosted apps). One of the challenges for this type of application is how to distribute it to end users.
This post will walk through creating a static AngularJS application (i.e. no back-end server) and how to create and publish a lean Docker container that serves the application content. I will mention some tooling but discussion of setting up a JS development environment is beyond the scope of this article. There are many resources that cover those topics.
Also note that even though I'm using AngularJS, any static web content can be distributed with this method.
Side Note on AngularJS
One of the major advantages of using AngularJS over the many JavaScript framework alternatives is its overwhelming popularity. Any question or issue you may encounter will typically be answered with a simple search (or two).
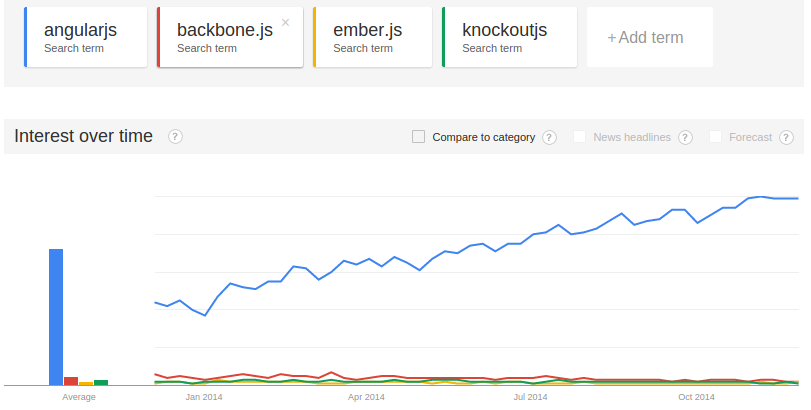
With the recent AngularJS 2.0 controversy it will be interesting to see if this trend continues.
Creating an AngularJS application
The easiest way to create a full-featured Angular application is with Yeoman. Yeoman is a Node.js module (npm) and along with its Angular generator creates a project that includes all of the build and test tools you'll need to maintain an application.
|
1 2 |
$ npm install -g yo $ npm install -g generator-angular |
Generate the Angular application with yo. Accepting all the defaults will include "Bootstrap and some AngularJS recommended modules." There's probably more functionality included then you'll need, but modules can be removed later.
|
1 2 3 |
$ mdir myapp $ cd myapp $ yo angular myapp |
The yo command will take a little while to complete because it has to download Angular and all of the modules and dependencies.
Start the server with Grunt (which needs to be installed separately).
|
1 |
$ grunt serve |
The application can be viewed in a browser at http://localhost:9000/#/:

Building the Application Distribution
After removing the 'Allo, Allo' cruft and creating your custom application create a distribution with:
|
1 |
$ grunt # You my need to add --force if jshint causes failures. |
This will create a dist directory that contains the static application content.
Creating and Publishing the Docker Container
The prerequisite is of course to install Docker and create a Docker Hub account (free). See Docker Installation Documentation.
A typical Ubuntu Docker container requires more than a 1GB download. A leaner Linux distribution is CoreOs. The coreos/apache container has a standard Apache server and is only ~250MB.
Add a Dockerfile file to the myapp directory:
|
1 2 3 4 |
# Build myapp server Docker container FROM coreos/apache MAINTAINER MyName COPY dist /var/www/ |
The key here is the COPY command which copies the content of the dist directory to the container /var/www directory. This is where the Apache server will find index.html and serve it on port 80 by default. No additional Apache configuration is required.
Create the docker container:
|
1 |
$ sudo docker build -t dockeruser/myapp . # This will create a 'latest' version. |
Output:

Now push the container to your Docker hub account:
|
1 |
$ sudo docker push dockeruser/myapp |
The dockeruser/myapp Docker container is now available for anyone to pull and run on their local machine or a shared server.
Starting the Application with Docker
The application can be started on a client system by downloading the running the dockeruser/myapp container.
|
1 2 |
# Instead of 9001, use 80 or 8080 if you want to provide external access to the application $ sudo docker run -d -p 9001:80 --name my-app dockeruser/myapp /usr/sbin/apache2ctl -D FOREGROUND |
The run command will download the container and dependencies if needed. The -d option runs the Docker process in the background while apache2ctrl is run in the container in the foreground. The application will be running on http://localhost:9001/#/.
To inspect the Apache2 logs on the running Docker instance:
|
1 2 3 4 5 |
$ sudo docker exec -it my-app /bin/bash root@bfba299706ad:/# ls /var/log/apache2/ access.log error.log other_vhosts_access.log root@bfba299706ad:/# exit # Exit the bash shell and return to host system $ |
To stop the server:
|
1 |
$ sudo docker stop my-app |
If you've pushed a new version of the application to Docker hub, users can update their local version with:
|
1 |
$ sudo docker pull dockeruser/myapp |
This example shows how Docker containers can provide a consistent distribution medium for delivering applications and components.





