Google recently open sourced Protocol Buffers: Google's Data Interchange Format (documentation, code download). What are Protocol Buffers?
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler.
The documentation is complete and worth a quick read through. A complete analysis of PB vs. XML can be found here: So You Say You Want to Kill XML.....
As discussed, one of the biggest drawbacks for us .NET developers is that there is no support for the .NET platform. That aside, all of the issues examined are at the crux of why interoperability is so difficult. Here are some key points from the Neward post:
- The advantage to the XML approach, of course, is that it provides a degree of flexibility; the advantage of the Protocol Buffer approach is that the code to produce and consume the elements can be much simpler, and therefore, faster.
- The Protocol Buffer scheme assumes working with a stream-based (which usually means file-based) storage style for when Protocol Buffers are used as a storage mechanism. ... This gets us into the long and involved discussion around object databases.
- Anything that relies on a shared definition file that is used for code-generation purposes, what I often call The Myth of the One True Schema. Assuming a developer creates a working .proto/.idl/.wsdl definition, and two companies agree on it, what happens when one side wants to evolve or change that definition? Who gets to decide the evolutionary progress of that file?
Anyone that has considered using a "standard" has had to grapple with these types of issues. All standards gain their generality by having to trade-off for something (speed, size, etc.). This is why most developers choose to build proprietary systems that meet their specific internal needs. For internal purposes, there's generally not a need to compromise. PB is a good example of this.
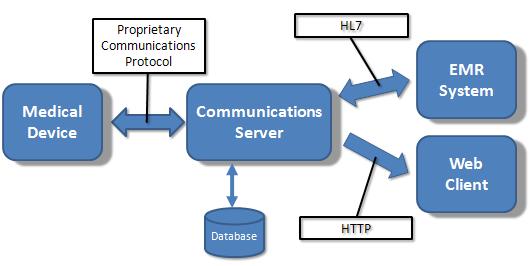
This also seems to be true in the medical device industry. Within our product architectures we build components to best meet our customer requirements without regard for the outside world. Interfacing with others (interoperability) is generally a completely separate task, if not a product unto itself.
Interoperability is about creating standards which means having to compromise and make trade-offs. It would be nice if Healthcare interoperability could be just a technical discussion like the PB vs. XML debate. This would allow better integration of standards directly into products so that there would be less of the current split-personality (internal vs. external needs) development mentality.
Another thing I noticed about the PB announcement -- how quickly it was held up to XML as a competing standard. With Google's clout, simply giving it away creates a de facto standard. Within the medical connectivity world though, there is no Google.
I've talked about this before, but I'm going to say it again anyway. From my medical device perspective, with so many confusing standards and competing implementations the decision on what to use ends up not being based on technical issues at all. It's all about picking the right N partners for your market of interest, which translates into N (or more) interface implementations. This isn't just wasteful, it's also wrong. Unfortunately, I don't see a solution to this situation coming in the near future.