
In this mornings paper:

😆
We tend to focus a lot of attention on tools and methodologies for improving software quality. I thought it would be worth while taking a step back to try to understand what the root causes of software defects are. Fortunately there has been decades of research that have analyzed the most common sources of software defects.
After also looking at some related development sins, I'll summarize what this new understanding means to me as a software developer.
An often sited article in IEEE Computer is Software Defect Reduction Top-10 List (Vol. 34, Issue 1, January 2001, 135-137) . Here's a summary (from Software Engineering: Barry W. Boehm's Lifetime Contributions to Software Development, Management, and Research):
This list is based on empirical research and is a good starting point for understanding how to avoid predictable pitfalls in the software development process.
A broader perspective is provided by Pursue Better Software, Not Absolution for Defective Products -- Avoiding the "Four Deadly Sins of Software Development" Is a Good Start. Here are the four deadly sins:
The First Deadly Sin: Sloth -- Who Needs Discipline?
The Second Deadly Sin: Complacency -- The World Will Cooperate with My Expectations.
The Third Deadly Sin: Meagerness -- Who Needs an Architecture?
The Fourth Deadly Sin: Ignorance -- What I Don’t Know Doesn’t Matter.
The SEI article concludes:
We believe that the practice of software engineering is sufficiently mature to enable the routine production of near-zero-defect software.
🙂 How can you not smile (or even LOL) at that statement? Despite that, I like the reduction of the problem into its most basic elements: human shortcomings. That's why the conclusion is so preposterous -- software development is a human activity, and a complex one at that. You're trying to produce a high quality software solution that meets customer expectations, which is a difficult thing to do.
Another list of software development sins can be found in The 7 Deadly Sins of Software Development.
#1 - Overengineering (in complexity and/or performance)
#2 - Not considering the code's readership
#3 - Assuming your code works
#4 - Using the wrong tool for the job
#5 - Excessive code pride
#6 - Failing to acknowledge weaknesses
#7 - Speaking with an accent (naming conventions)
There are some tool/language specific items here, but this list generally follows the same trend of discovering typical developer shortcomings that can be avoided.
Another source of software defects is poor project planning. More sins (deadly again) can be found in the Steve McConnell article: Nine Deadly Sins of Project Planning.
It's pretty easy to see from these categorizations where a lot of the software development and management techniques, tools, and practices came from. As you might have expected, many are focused on human behavior and communication as a key component for improving software quality. For example, take the Agile Manifesto:
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
This vision is very telling about what the manifesto writers considered to be a primary cause of software defects.
Another perspective is Fred Brooks' famous 1986 'No Silver Bullet' paper (also see here) that distinguishes "accidental" repetitive tasks from "essential" tasks. From the article:
There is no single development, in either technology or in management technique, that by itself promises even one order-of-magnitude improvement in productivity, in reliability, in simplicity.
Even after twenty years of significant progress in software engineering, I believe that this is still a true statement.
Conclusion:
There are many complex factors that contribute to software defects. There is clearly no one-size-fits-all solution. As a developer, this means that I have to:
I guess I've been obsessed with interoperability (or lack thereof) lately.
Definitions:
Dictionary interoperability 1,0,0,0;interoperability=555039
- Main Entry: in·ter·op·er·a·bil·i·ty
- Pronunciation: \ˌin-tər-ˌä-p(ə-)rə-ˈbi-lə-tē\
- Function: noun
- Date: 1977
- : ability of a system (as a weapons system) to work with or use the parts or equipment of another system
The ability of two or more systems or components to exchange information and to use the information that has been exchanged.
From the National Alliance for Health Information Technology (NAHIT) definition:
In healthcare, interoperability is the ability of different information technology systems and software applications to communicate, to exchange data accurately, effectively, and consistently, and to use the information that has been exchanged.
The four NAHIT levels are:
From IEEE 1073 (Point of Care Medical Device Communications) and IEEE-USA Interoperability for the National Health Information Network (NHIN) -- original definitions are from IEEE Standard Computer Dictionary: Compilation of IEEE Standard Computer Glossaries, IEEE, 1990:
Functional: The capability to reliably exchange information without error.
An architecture is the conceptual design of the system. Systems inter-operate if their architectures are similar enough that functions that execute on one system execute identically (or nearly identically) on another system.
Shared methods refer to the processes and procedures that a system performs. To ensure interoperability, these operations must be capable of being performed identically at any point in the network, regardless of implementation.
A shared framework is a shared set of goals and strategies. Stakeholders must agree on a shared set of goals and approaches to implementation.
Semantic: The ability to interpret, and, therefore, to make effective use of the information so exchanged.
Shared data types refer to the types of data exchanged by systems. Interoperability requires that systems share data types on many different levels, including messaging formats (e.g. XML, ASCII), and programming languages (e.g. integer, string).
Shared terminologies refer to establishing a common vocabulary for the interchange of information. Standardized terminology is a critical requirement for healthcare applications to ensure accurate diagnosis and treatment, and has led to developing standards such as SNOMED-CT.
Shared codings refer to establishing standard encodings to be shared among systems. Codings refer not only to encoding software functions, but also to encoding medical diagnoses and procedures for claims processing purposes, research, and statistics gathering (e.g. ICD9/10, CPT).
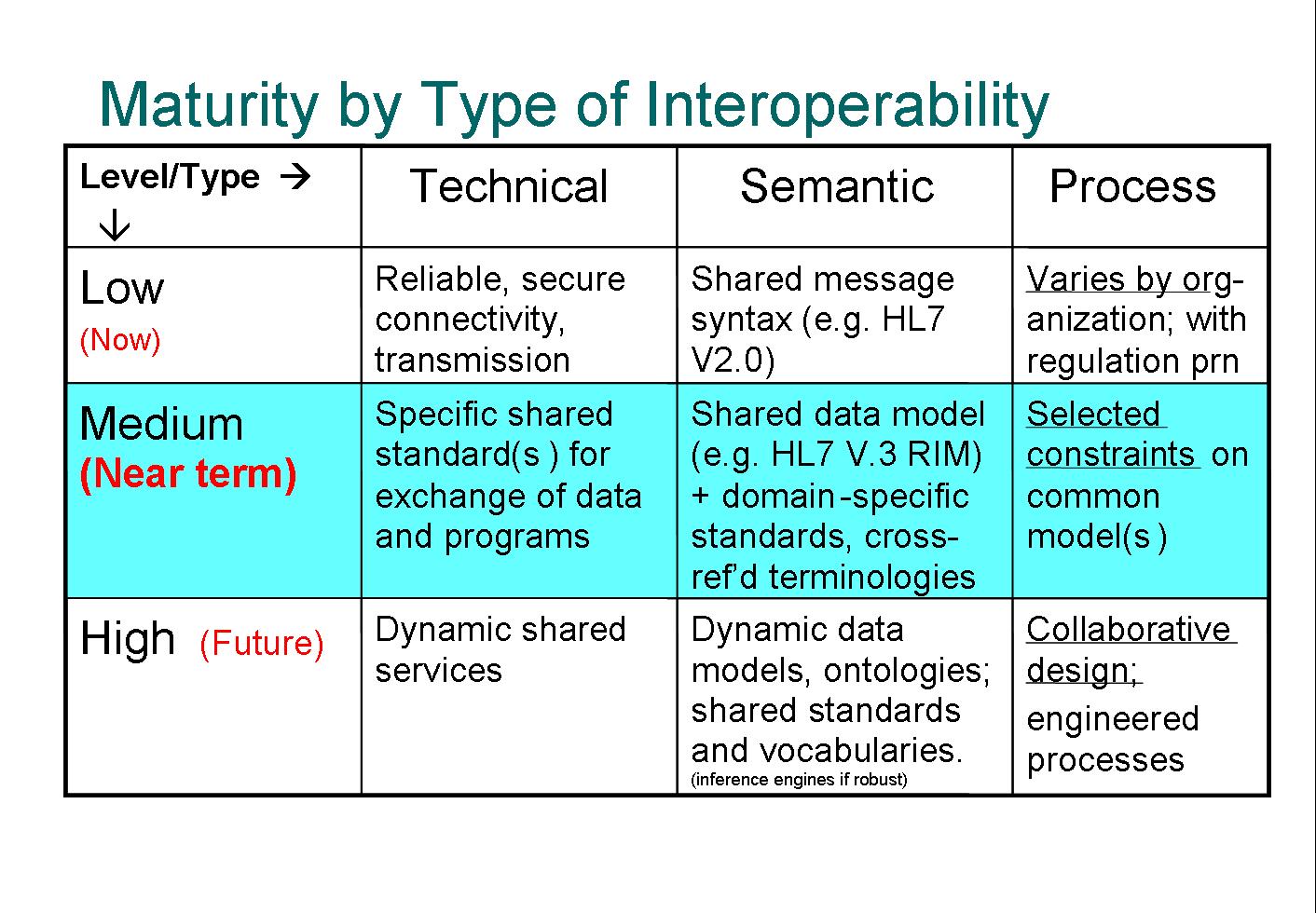
At Healthcare Informatics Technology Standards Panel (HITSP) I came across a maturity model of interoperability types from the Mayo Clinic. Even though this table is taken out of context, the Technical-Semantic-Process model shows yet another view of interoperability.
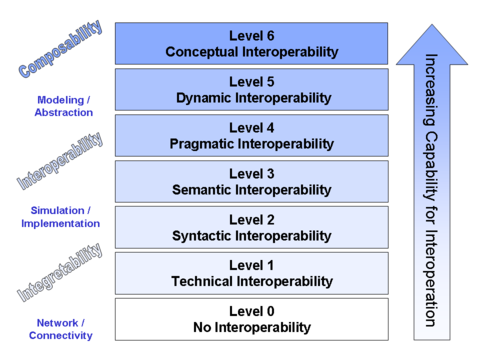
There are also a number of Models of Interoperability that describe abstract interoperability. For example, a finer grained layered model is called Conceptual Interoperability. This model encompasses the previous healthcare IT definitions:
Besides these definitions there are many articles (and books), especially as it relates to healthcare and EMR/EHR, that espouse the benefits of interoperability.
From a broader software industry point of view you can imagine the number and variety of issues that a company like Microsoft has to deal with. They claim Interoperability by Design. Of course Microsoft has gotten a lot of attention about their push to get Open Office XML (OOXML) approved as a standard by EMCA -- some quite negative:

Even though I don't believe the healthcare industry has the equivalent of 'Da Bill' (or maybe it does?), this points out one of the necessary components for the implementation of interoperability: standards.
I was on an ASTM standards committee a number of years ago (E1467-94, now superseded) , so I have some understanding of how difficult it is to get consensus on these types of issues. The process is long (years) and can sometimes be contentious. Even after a standard has been balloted and approved, there's no guarantee that it will be widely adopted.
Summary:
In my previous post on this subject I pointed out the plethora of healthcare IT standards and their confusing inter-relationships. The definitions of interoperability can be just as confusing. Each of the different models has a slightly different way of looking at the same thing. This is certainly one reason why there are so many overlapping standards.
Conculsion:
Interoperability in healthcare IT is multi-faceted and complex. This makes it difficult to agree upon exactly what it is (the definition) and even harder to develop the standards on which to base implementations.
Last night I went to the launch of the San Diego Connected Systems SIG (and here). Brian (along with Chris Romp) gave a great overview of BizTalk Server 2006 R2.
I have never used BizTalk and had little knowledge of its capabilities going in. BizTalk reference material and articles can be found in numerous places on the web -- a good summary is Introducing BizTalk Server 2006 R2 (pdf).
My major take-aways from the presentation were:
Because of its message handling architecture it's easy to see how HL7 translation and routing could be accomplished. Microsoft provides accelerators (pre-defined schema, orchestration samples, etc.) for HL7 and HIPAA for this purpose.
It's not hard to understand the importance of BizTalk in the larger Enterprise space. It appears to be benefiting from its years of prior experience and continued integration with other evolving Microsoft technologies. Overall, I was very impressed with BizTalk.
A Note on Special Interest Groups
I'm not only lucky to have a SIG like this in the area, but it's also great to have people as knowledgeable (and friendly) as Brian and Chris running it. Great job guys!
I would encourage everyone to seek out and attend their local user/developer group meetings. Don't just go for the free pizza (which usually isn't that good anyway) -- it's a great way to improve yourself both technically and professionally. You'll also get to meet new people that have the same interests as you.
I think that getting exposure to technologies that you don't use in your day-to-day work can be just as rewarding as becoming an expert in your own domain. Learning about cutting-edge software (or hardware) is exciting no matter what it is. That new knowledge and perspective also has the potential to lead you down roads that you might not have considered otherwise.
I found two related posts today:
The content of the Larry Lessig talk is interesting, but it's the presentation that's unique and engaging. The remixed videos are great.
In looking through some of the other TED offerings and I ran across a 2003 Jeff Hawkins presentation on Brain theory. I've been interested in his software company, Numenta, for a while now. They have implemented a hierarchical temporal memory system (HTM) model which is "a new computing paradigm that replicates the structure and function of the human neocortex." The talk is a broader look at why it has taken so long to develop a framework for how the brain works.
Jeff Hawkins has had an interesting career in non-neuroscience areas (pen-based and tablet computing, Handspring). Hopefully his memory-prediction model of human intelligence will lead to improved artificial intelligence software systems.
Or maybe that should be "non-interoperability"? Anyway, I have ranted in the past about the state of the EMR industry. I thought I'd add a little meat to the bone so you could better appreciate the hurdles facing device interoperability in healthcare today.
Here's a list of the standards and organizations that make up the many components of health information systems. I'm sure that I've missed a few, but these are the major ones:
Medical Coding
Organizations
Standards
This list does not include any of the underlying transport or security protocols. They are either data formatting (many based on XML) or specialized messaging systems.
The diagram below gives an overview of how many of these standards are related (from an IEEE-USA purchased e-book -- copying granted for non-commercial purposes):
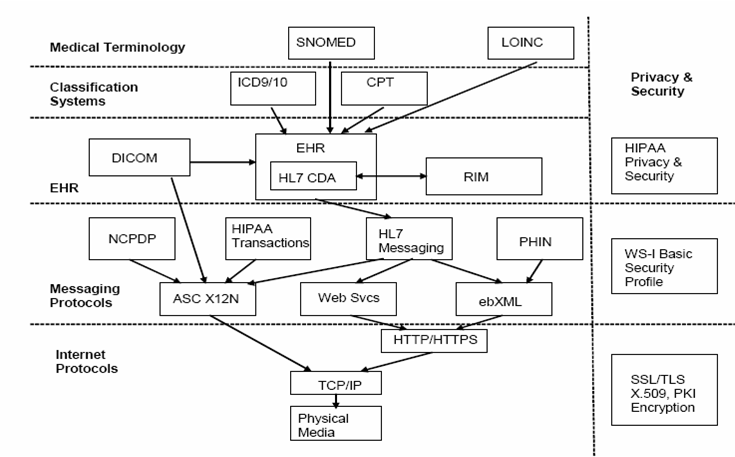
I don't know about you, but trying to make sense of all these standards and protocols is not an easy task. A discussion of next generation PHRs summarizes the situation well:
... not only is information scattered, but standards for defining and sharing the data are still evolving; where standards exist, many of them predate the Internet. Standards about how to define consistently the information (clinical standards) and to transmit and exchange the information (technical standards) are not yet formalized and agreed upon.
The point about predating the Internet is an important one. This particularly pertains to HL7 v2.x which still uses ASCII delimited messages for transmission over serial lines. For all you 21st century programmers that may have never seen one before, here's what an HL7 v2.x message looks like:
MSH|^~\&|AcmeHIS|StJohn|ADT|StJohn|20060307110111||ADT^A04
|MSGID20060307110111|P|2.4EVN|A04PID|||12001||Jones^John|
|19670824|M|||123 West St.^^Denver^CO^80020^USAPV1||O
|OP^PAREG^||||2342^Jones^Bob|||OP|||||||||2|||||||||||||||
||||||||||20060307110111|AL1|1||3123^Penicillin
||Produces hives~Rash~Loss of appetite
HL7 v3 uses XML for it's message format but it has not been widely adopted yet. A good history of HL7 v2 and v3, and an explanation of their differences, can be found here (pdf).
HL7 v2 is commonly used in hospitals to communicate between medical devices and EMR/HIS systems. Even though the communications framework is provided by HL7, new interfaces must still be negotiated, developed, and tested on a case-by-case basis.
Most of the large EMR companies provide HL7 interfaces, but many of the smaller ones do not. This is because hospitals are not their primary market so they don't generally need device interfaces. These EMRs are essentially clinical document management, patient workflow, and billing systems. The only external data they may deal with are scanned paper documents that can be attached to a patients record. The likelihood that they would conform to any of the standards listed above is low.
I'm not sure things will improve much with the recent PHR offerings from Microsoft (HealthVault) and Google (Google Health -- not yet launched) . Microsoft appears to be embracing some of these standards as discussed in Designing HealthVault’s Data Model, but there are a couple of telling comments:
Some of the data types we needed in order to support our partners’ applications where not readily available in the standards community.
Our types also allow each vendor to add “extensions” of their own making to item data – so to the extent that we are missing certain fields, they can be added – and the industry can rally around those extensions if it makes sense.
Microsoft says they are not the "domain experts", so they're leaving it to the industry to sort it all out. Great! This is probably the same attitude that got us to where we are today.
Hopefully you can now see why I've used the words "mess" and "chaos" to describe the current situation. The challenges facing interoperability in healthcare are immense.
Earlier today I was in my auto shop's waiting area while my car had its annual smog check. I started looking through the pile of magazines and came across the November 2007 issue of Popular Mechanics. To my amazement the cover article was on fMRI (functional magnetic resonance imaging) -- Thought Police: How Brain Scans Could Invade Your Private Life.
My previous discussion on Mind Reading Software was mostly concerned with techniques that used EEG signal processing. fMRI technology is summarized by the article:
The underlying technology involved in functional magnetic resonance imaging has been around for decades. What’s new is the growing sophistication in how it is being used. Inside a massive doughnut-shaped magnet, an fMRI scanner generates powerful fields that interact with the protons inside a test subject’s body. The hemoglobin molecules in red blood cells, for instance, exhibit different magnetic properties depending on whether they are carrying a molecule of oxygen. Since regions of the brain use more oxygen when they’re active, an fMRI scanner can pinpoint which areas are busiest at a given moment. These can be correlated with our existing anatomical understanding of the brain’s functions—and, as our knowledge of these functions improves, so does the accuracy of neuroimaging data. With fMRI, then, researchers can see what is going on across the entire brain, almost in real time, without danger or discomfort to the test subject.
As the title indicates, most of the article discusses the on-going debate over the use of fMRI for things like lie-detection. There's also an overview of some fMRI research activities.
NPR's Morning Edition also ran a story on this last week: Neuroscientist Uses Brain Scan to See Lies Form.
Just like with EEG-based techniques, fMRI "mind reading" provokes many legal and ethical questions. I think there is legitimate cause for concern when companies (like No Lie MRI) are making claims that could affect people's lives.
I used quotation marks around mind reading because the current state of these technologies is not anywhere close to being able to know a person's memories, thoughts, or intentions. I wouldn't be too worried about having your private life invaded. Not for a long while anyway.
Update (05-Nov-2007):
I'm not sure if what they're doing in the UK is any different, but this technology is certainly pushing the legal system. See Groundbreaking Experiments Could Lead To New Lie Detector.
Things are getting back to normal here in San Diego -- except if you were one of the those that lived or worked in the over 1500 lost homes or businesses. 🙁
It's amazing that it's only been a week and the wildfires are already old news . Nevertheless, the NASA satellite images are remarkable:
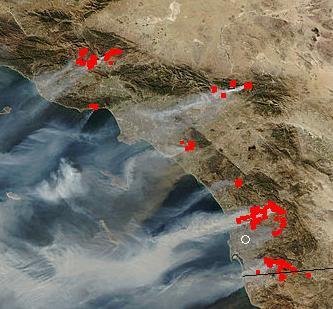
These latest images, captured by NASA satellites on the afternoon of October 22, show the thick, billowing smoke coming off the numerous large fires and spreading over the Pacific Ocean. Fire activity is outlined in red.
The small white circle is the approximate location of our office. Downtown SD is on the bay just to the southwest. As you can see, the fires to the north and south didn't have much affect on us (and downtown) because the Santa Ana winds were blowing so strong directly from east to west.
The large fire area to the north (which started in Witch Creek) is heavily populated and is where most of the property loss occurred. That fire ended up getting to within several miles of the ocean. It's still hard to believe that over 500,000 people were evacuated from their homes.
I'm originally from the Midwest and thought tornadoes were bad -- hunkered down in the basement with the wind and rain battering the house and sirens blaring in the distance. Even if there were basements in CA I don't think they would help a whole lot in one of these fires. Your only option is to get out.
Here's another NASA image from about the same time (from here):

Wow!
FMEA (Failure Mode and Effects Analysis) is a regular part of our development process (we call it "Hazard Analysis"), but I was unfamiliar with FRACAS (Failure Reporting, Analysis, and Corrective Action Systems) until I ran across this: 10/21/2007 FRACAS? – Never heard of it.
I'd also never heard of "software reliability growth". The model is described here, and there are also some other good links available from the Google search.
I'm a software developer, not a quality systems person. According to Jan, even medical device quality people are not that familiar with these methods. In addition to Jan's explanation for this, one reason I (or others) might not have heard of these is that my experience has been exclusively in Class II non-invasive diagnostic devices. The development of Class III life support and implantable devices is a whole different animal when in comes to quality control rigor.
CAPA's (Corrective and Preventive Action) are of course part of the standard FDA Quality System Regulations (§ 820.100). These procedures are primarily implemented to deal with quality problems after the product has been released to the field.
The concept of preventing recurrence of observed errors (FRACAS) during the development process is certainly an interesting one. The difference between CAPA and FRACAS is similar to the argument I made regarding Software Forensics -- these techniques should be used to ensure quality before the product is released.
When I started this blog I told myself that I was going stay on topic. I've strayed a couple of times but blogging about blogging was always very high on the off-topic list.
Then I read How To Achieve Ultimate Blog Success In One Easy Step by Jeff Atwood. He really hits the nail on the head about the motivation and benefits of blogging. So now I'm forced to break my own rules again. [That's actually one of the nice things about having your own blog, you get to make up your own rules -- or break them -- anytime you want.] If you have an interest in starting a blog, read his post and the many links.
From his Fear of Writing post:
It's like exercise. No matter how out of shape you are, if you exercise a few times a week, you'll inevitably get fitter. And if you write a small blog entry a few times every week, you're bound to become a better writer.
One of the reasons I started blogging was because I've always wanted to be a better writer. Whenever I read a great article or book I'm always envious of the writer's talent. It's like watching an athlete: you know how great they are by how easy they make extraordinary feats look. I will never be a superstar (like Coding Horror), but I have so much room for improvement it's a good bet that I'll get better.
Writing is hard. At least it is for me. You might think that you could use some of your programming techniques and skills to facilitate writing. I haven't found that to be the case at all. The whole flow of writing is completely different than programming. When you develop code you're typically implementing multiple trains of interconnected logic in parallel. In order to do this you're jumping back and forth between those pieces of logic.
When you blog, the topic you're discussing may have distinct points or categories, but writing about it requires a single stream of coherent thought. Not only that, you have to be able to write understandable English sentences. All of this is no easy task for an Engineer. Thank goodness for spell-checkers anyway.
Besides the writing part, technology blogging is also a challenge. For some, just finding unique topics can be difficult. This seems to be especially true for programming blogs, mostly because there are so many of them. Fortunately, within my areas of interest I have many topics to discuss that aren't already being covered by hundreds of others.
Actually, it would be nice to have some more company, so I'll ask the same question as Jeff:
So when was the last time you wrote a blog post?
