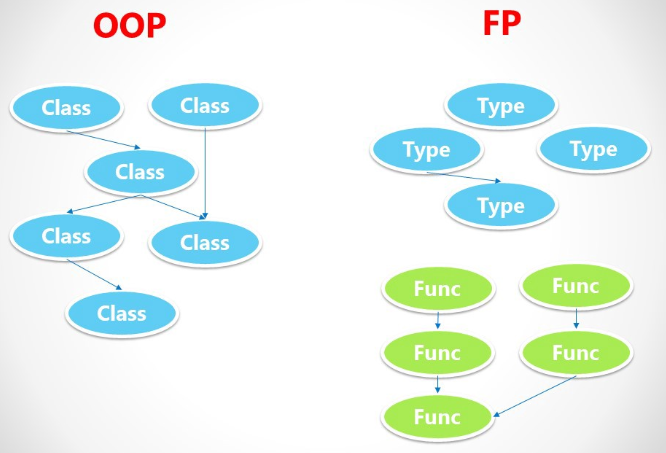
I've always viewed functional programming (FP) from afar, mostly because object-oriented programming (OOP) is the dominant development methodology I've been using (Java, Ruby, C#, etc.) for many years. A majority of the articles I've read on FP have statements like this:
I've always viewed functional programming (FP) from afar, mostly because object-oriented programming (OOP) is the dominant development methodology I've been using (Java, Ruby, C#, etc.) for many years. A majority of the articles I've read on FP have statements like this:
If you’ve never tried functional programming development, I assure you that this is one of the best time investments you can make. You will not only learn a new programming language, but also a completely new way of thinking. A completely different paradigm.
Switching from OOP to Functional Programming gives an overview of the differences between FP and OOP. It uses Scala and Haskell for the FP example code, but I think it still does a good job of getting the major concepts across:
I do not think that FP, or any single paradigm/language/framework/etc. for that matter, is a silver bullet. On the contrary, I'm a true believer in the "right tool for the job" philosophy. This is particularly true in the software industry where there is such a wide variety of problems that need to be solved.
This view for programming paradigms is cute but is actually misleading:
As a developer, it's important to always to be learning new problem-solving approaches. I.e. adding new tools to your tool-belt. This will not only allow you to select the best solution(s) for the job, but you'll be better able to recognize the trade-offs and potential problem areas that might arise with any solution. I think understanding FP concepts will make you a better programmer, but not necessarily because you are using FP techniques and tools.
Functional Programming Is Not a Silver Bullet sums it up best:
Don’t be tricked into thinking that functional programming, or any other popular paradigm coming before or after it, will take care of thinking about good code design instead of us.
The purpose of this article is to present my own experiences in trying to use Clojure/FP as an alternative approach to traditional OOP. I do not believe there is anything here that has not already been covered by many others, but I hope another perspective will be helpful.
Lisp
I chose a Lisp dialect for this exploration for several reasons:
- I have some Lisp experience from previous projects and was always impressed with its simplicity and elegance. I really wanted to dig deeper into its capabilities, particularly macros (code as data - programs that write programs). See Lisp, Smalltalk, and the Power of Symmetry for a good discussion of both topics.
- I'm also a long-time Emacs user (mostly for org-mode) so I'm already comfortable with Lisp.
- This profound advice:
For all you non-Lisp programmers out there, try LISP at least once before you die. You will not regret it.
Lisp has a long and storied history (second oldest computer language behind Fortran). Here's a good Lisp historical read: How Lisp Became God's Own Programming Language.
I investigated a variety of Lisp dialects (Racket, Common Lisp, etc.) but decided on Clojure primarily because it has both JVM and Javascript (ClojureScript) support. This would allow me more opportunity to use it for real-world projects. This is also why I did not consider alternative FP languages like Haskell and Erlang.
Lastly, the obligatory XKCD cartoon that makes fun of Lisp parentheses (which I address below):

Why Clojure?
Why Clojure? I’ll tell you why… provides a good summary and references:
- Simplicity
- Java Interoperability
- REPL (Read Eval Print Loop)
- Macro
- Concurrency
- ClojureScript
- Community
Here are some more reasons from Clojure - the perfect language to expand your brain?
- Pragmatism (videos at Clojure TV)
- Data processing: Sequences and laziness
- Built-in support for concurrency and parallelism

There are also many good articles that describe the benefits of FP (immutable objects, pure functions, etc.).
Clojure (and FP) enthusiasts claim that their productivity is increased because of these attributes. I've seen this stated elsewhere, but from the article above:
Clojure completely changed my perspective on programming. I found myself as a more productive, faster and more motivated developer than I was before.
It also has high praise from high places:

Who doesn't want to hang out with the smart kids?
Clojure development notes
The following are some Clojure development observations based on both the JSON Processor (see below) and a few other small ClojureScript projects I've worked on.
The REPL
The read-evaluate-print-loop, and more specifically the networked REPL (nREPL) and its integration with Emacs clojure-mode/cider is a real game-changer. Java has nothing like it (well, except for the Java 9 JShell, which nobody knows about) and even Ruby's IRB ("interactive ruby") is no match.
Being able to directly evaluate expressions without having to compile and run a debugger is a significant development time-saver. This is a particularly effective tool when you are writing tests.
Parentheses
A lot a people (like XKCD above) make fun of the Lisp parentheses. I think there are two considerations here:
- Keeping parentheses matched while editing. In Clojure, this also includes {} and []. Using a good editor is key - see Top 5 IDEs and text editors for Clojure. For me, Emacs smartparens in strict mode (i.e. don't allow mismatches at all), plus some wrap/unwrap and slurp/barf keyboard bindings, all but solved this issue.
- When reading Lisp code, I think parentheses get a bad rap. IMO, the confusion has more to do with the difference in basic Lisp flow control syntax than stacked parentheses. Here's a comparison of Ruby and Lisp if syntax:
|
1 2 3 4 5 |
if var.nil? do_nil_stuff(var) else do_not_nil_stuff(var) end |
|
1 2 3 |
(if (nil? var) (do-nil-stuff var) (do-not-nil-stuff var)) |
Once you get used to the differences, code is code. More relevantly, bad code is bad code no matter what language it is. This is important. Here's a good read on the subject: Effective Mental Models for Code and Systems ("the best code is like a good piece of writing").
Project Management
Leiningen ("automating Clojure projects without setting your hair on fire") is essentially like Java's Maven, Ruby's Rake, or Python's pip. It provides dependency management, plug-in support, applications/test runners, customized tasks, etc.
Coming from a Maven background, lein configuration management and usage made perfect sense. The best thing I can say is that it always got the job done, and even more important, it never got in the way!
Getting Answers
I found the documentation (ClojureDocs) to be very good for two reasons:
- Every function page has multiple examples, and some are quite extensive. You typically only need to see one or two good examples to understand how to use a function for your purposes. Having to read the actual function description is rarely needed.
- Related functions. The "SEE ALSO" section provides links to functions that can usually improve your code: if → if-not, if-let, when,... This is very helpful when you're learning a new language.
I lurked around some of the community sites (below). The threads I read were respectful and members seemed eager to help.
Clojure Report Card
Language: A
On the whole, I was very pleased with the development experience. Solving problems with Clojure really didn't seem that much different from other languages. The extensive core language capabilities along with the robust ecosystem of libraries (The Clojure Toolbox) makes Clojure a pleasure to use.
I see a lot of potential for practical uses of Clojure technologies. For example, Clojurified Electron plus reagent-forms allowed me to build a cross-platform Electron desktop form application in just a couple of days.
I was only able to explore the tip of the Clojure iceberg. Based on this initial experience, I'm really looking forward to utilizing more of the language capabilities in the future.
FG vs OOP: B
My expectations for FP did not live up to what I was able to experience in this brief exploration. The lower grade reflects the fact that the Clojure projects I've worked on were not big enough to really take advantage of the benefits of FP described above.
This is a cautionary tale for selecting any technology to solve a problem. Even though you might choose a language/framework that advertises particular benefits (FP in this case), it doesn't necessarily mean that you'll be able to take advantage of those benefits.
This also highlights the silver bullet vs good design mindset mentioned earlier. To be honest, I somehow thought that Clojure/FP would magically solve problems for me. Of course, I was wrong!
I'm sure this grade will improve for future projects!
Macros: INC (incomplete)
I was also not able to fully exercise the use of macros like I wanted to. This was also related to the nature of the projects. I normally do DSL work with Ruby, but next time I'll be sure to try Clojure instead.
TL;DR
The rest of this article digs a little deeper into the differences between the Ruby and Clojure implementations of the JSON Processor project described below.
At the end of the day, the project includes two implementations of close to identical functionality that can be used for comparison. Both have:
-
- Simple command line parsing and validation
- File input/output
- Content caching (memoization)
- JSON parser and printer
- Recursive object (hash/map) traversal
The Ruby version (~57 lines) is about half the size of Clojure (~110 lines). This is a small example, but it does point out that Ruby is a simpler language and that there is some overhead with the Clojure/FP programming style (see Pure Functions, below).
JSON Processor
The best way to learn a new language is to try to do something useful with it. I had a relatively simple Ruby script for processing JSON files. Reproducing its functionality in Clojure was my way of experiencing the Clojure/FP approach.
The project is here: ![]() json-processor
json-processor
The Ruby version is in the ./ruby, while the Clojure version is in ./src/json_processor. See the README.md file for command line usage.
The processor is designed to simply detect a JSON key that begins with "include" and replace the include key/value pair with the contents of a file's (./<current_path>/value.json) top-level object. Having this include capability allows reuse of JSON objects and can improve management of large JSON files.
So, if two files exist:
|
1 2 |
base.json level1.json |
and base.json contains:
|
1 2 3 4 |
{ "baseString" : "zero", "include" : "level1" } |
And level1.json contains:
|
1 2 3 4 5 6 |
{ "level1" : { "level1String" : "string1", "level1Float" : 45.67 } } |
After running base.json through the processor, the contents of the level1 object in the level1.json file will replace "include":"level1", with the result being:
|
1 2 3 4 5 |
{ "baseString" : "zero", "level1String" : "string1", "level1Float" : 45.67 } |
Also, included files can contain other include files, so the implementation is a good example of a recursive algorithm.
There are example files in the ./test/resources directory that are slightly more complex and are used for the testing.
Development Environment
- Ruby 2.4+
- Java 8
- Clojure (1.9+)
- Leiningen (2.8.3)
- A decent Lisp IDE/editor. I use Emacs with clojure-mode, cider, and smartparens
Immutability
Here's the Ruby recursive method:
|
21 22 23 24 25 26 27 28 29 30 31 32 33 |
def process_json(obj) if obj.kind_of?(Hash) obj.clone.each { |k, v| if k.start_with?('include') obj.delete(k) get_json_content(File.join(@dir_name,v)).values.first .each { |k, o| obj[k] = process_json(o) } end process_json(v) } end obj end |
The passed-in object is purposely modified. The Ruby each function is used to iterate over each key/value pair and replace the included content as needed. It deletes the "include" key/value pair and adds the JSON file content in its place. Again, the returned object is a modified version of the object passed to the function.
|
40 41 42 43 44 45 46 47 48 49 50 |
(defn process-json "Process a JSON object" ([base-dir obj] (reduce-kv (fn [m k v] (if (is-a-map? v) (assoc m k (process-json base-dir v)) (if (s/starts-with? (name k) "include") (merge m (get-include-content base-dir v)) (assoc m k v)))) {} obj))) |
The immutability of Clojure objects and use of reduce-kv means that an all key/value pairs need to be added to the 'init' ( m) collection ( (assoc m k v) ). This was not necessary for the Ruby implementation.
A similar comparison, but with more complexity and detailed analysis, can be found here: FP vs. OO List Processing.
Pure Functions
You'll notice in the Ruby code that the class variable @dir_name, which is created in the constructor, is used to create the JSON file path:
get_json_content(File.join(@dir_name,v)).values.first
The Clojure code has no class variables, so base_dir must be passed to all methods, like in the process-json-file macro:
`(process-json ~base-dir (get-json ~base-dir ~file-name))))
To an OOP developer, having base_dir as a parameter in every function definition may seem redundant and wasteful. The Functional point-of-view is that:
- Having mutable data (@dir_name) can be the source of unintended behaviors and bugs.
- Pure functions will always produce the same result and have no side effects, no matter what the state of the application is.
These attributes improve reliability and allow more flexibility for future changes. This is one of the promises of FP.
Final Thought
I highly recommend giving Clojure a try!
Bad joke:
I have slurped the Clojure Kool-Aid and can now only spit good things about it.
Sorry about that. 🙂
UPDATE (22-Aug-19): More Clojure love from @unclebobmartin: Why Clojure?

 In a perfect world, you'd be able to create a greenfield Angular SPA from scratch. In the real world, that's usually not the case. That legacy web application has way too much baggage to realistically convert it to an SPA in a single shot. This is particularly true if you're currently using server-side rendering with (e.g.) JSP or Rails technology.
In a perfect world, you'd be able to create a greenfield Angular SPA from scratch. In the real world, that's usually not the case. That legacy web application has way too much baggage to realistically convert it to an SPA in a single shot. This is particularly true if you're currently using server-side rendering with (e.g.) JSP or Rails technology.